- Kaggle 사이트에서 머신러닝 개발환경(jupyter notebook)을 제공한다.
- Kaggle competition에서 제공하는 DataSet은 100G가 넘어가는게 많은데, 캐글 개발환경에서 바로 DataSet 접근이 가능하다.
- 1주 최대 38시간 GPU 사용이 가능하고, 주마다 Reset된다.(notebook생성할때 어디서 봤는데 다시 못찾겠다;;)
메뉴진입
- 회원가입 -> Competion -> Summit Predictions -> New Notebook
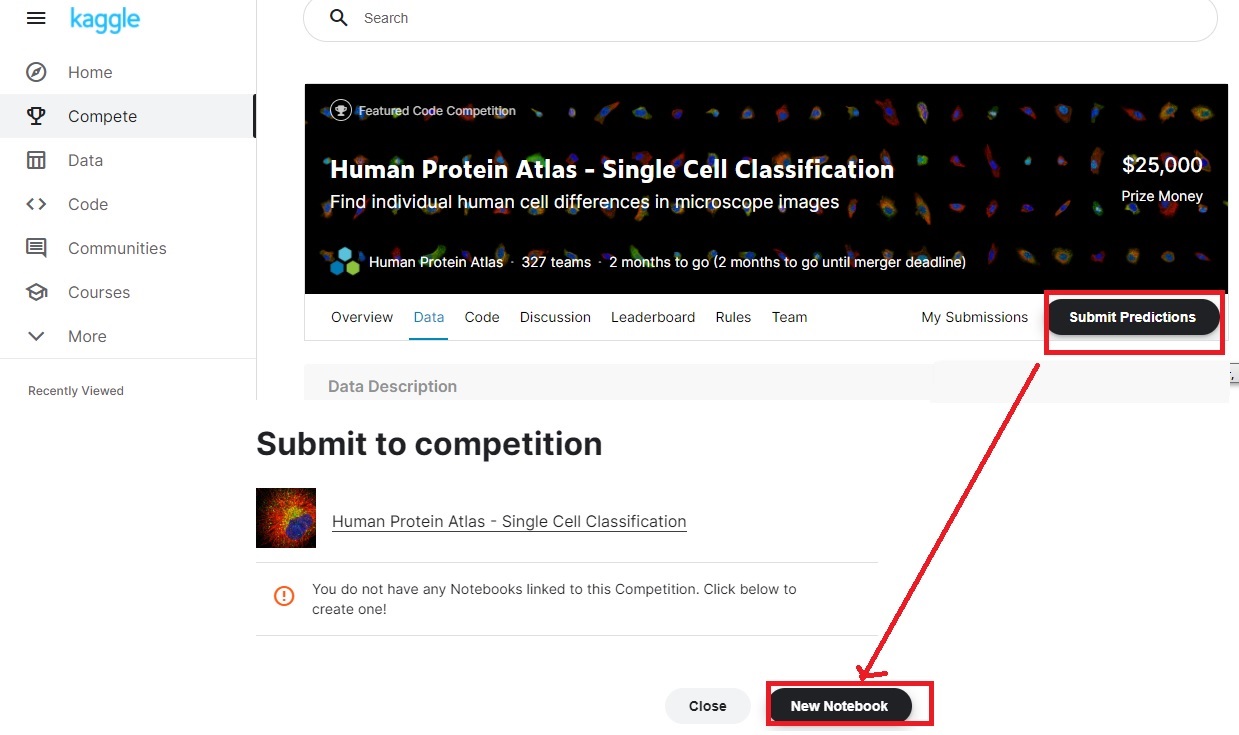
제약사항 확인
일반 제약사항
- GPU: 1주 38시간(1주일단위 초기화되어 다시 38시간 사용가능)
- 20G까지 쓰기 가능
You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using “Save & Run All”
GPU 설정
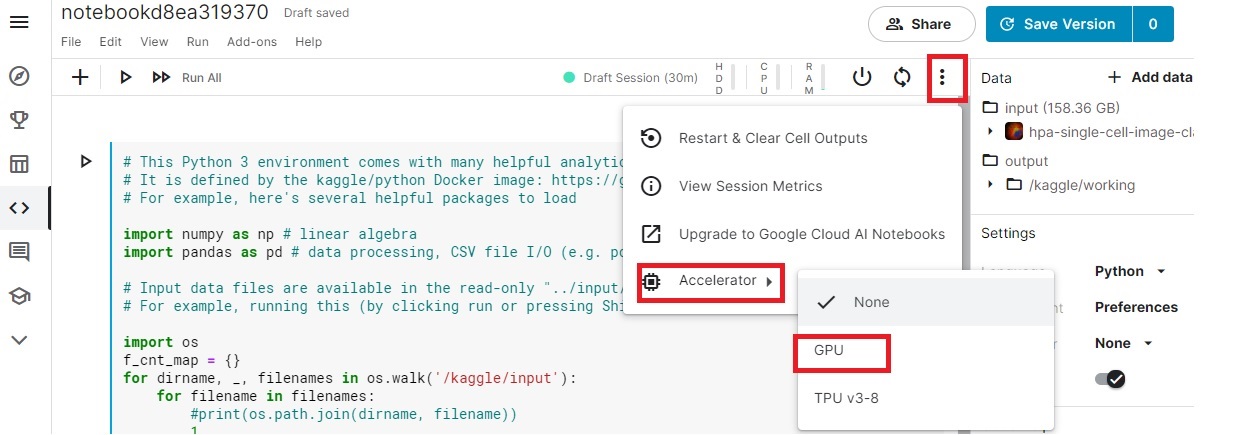
Data 추가

Data접근
예제코드 제공
- 이미 아래와 같이 예제코드 제공하고, 파일count 체크하는 로직을 추가하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
f_cnt_map = {}
for dirname, _, filenames in os.walk('/kaggle/input'):
f_cnt_map[dirname] = len(filenames)
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
for idx, d_name in enumerate(f_cnt_map.keys()):
print("idx:", idx, " ,d_name:", d_name, " ,f_cnt:", f_cnt_map[d_name])
print("---")
prn_cnt = 0
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
prn_cnt + = 1
if(prn_cnt>=30) break샘플파일 보기
1
2
3
4
5
6- 1. 파일명 확인
!ls /kaggle/input/hpa-single-cell-image-classification/test/
- 2. 이미지 보기
# 이미지 샘플(test-set) 보기!
img_array = np.array(Image.open('/kaggle/input/hpa-single-cell-image-classification/test/0040581b-f1f2-4fbe-b043-b6bfea5404bb_blue.png'))
plt.imshow(img_array)
Label 정보 확인
1 | #1-1. 그룹별 갯수 확인 |